Note
This technote is not yet published.
1 Context¶
The report of the Observatory Electronic Logging Working Group Report identifies a number of requirements to support the exchange of information between the different technical teams and operations xdepartments during the commissioning and the operation of the observatory.
This document proposes an architecture and implementation approach that would fulfil these requirements.
2 Overview & Departures¶
The requirements set out in LSE-490 generally fall into the following three categories:
- A list of “inputs” that describe information that should be available/discoverable (“What happened”)
- A webapp that allows for guided interactive exploration/discovery of the available data inputs (“Why did it happen?”)
- Ways of directing, collating and presenting/reporting the inputs to various audiences (“Who needs to know”)
There are also two “global” requirements for availability that we will come to later (see Networked Architecture).
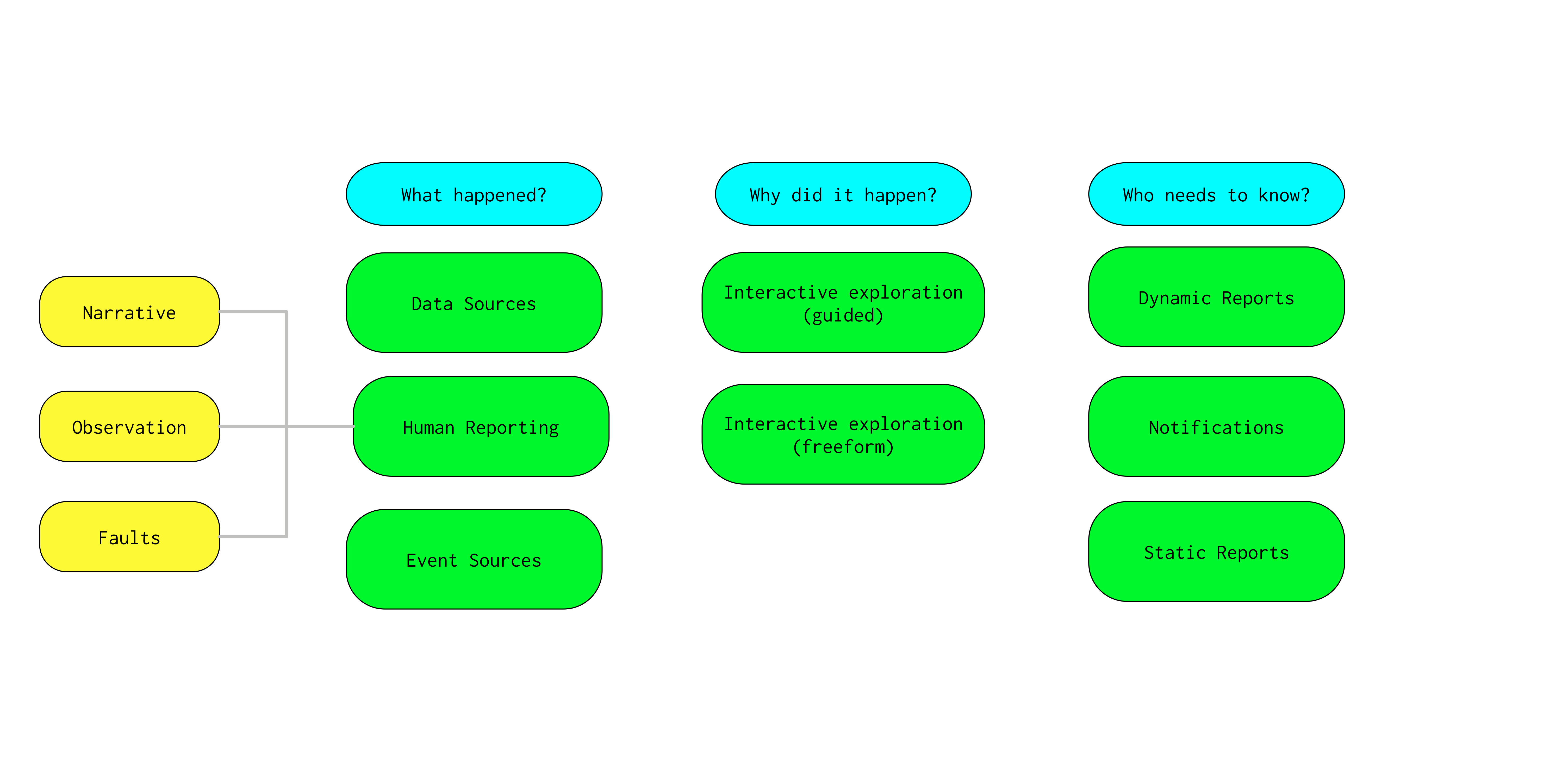
Figure 1 Illustration of the areas of the Working Group concern.
While LSE-490 purports to describe a logging “system”, the servicing of the requirements listed in fact involves a number of observatory software systems (most extant, some not) that participate either as data/metadata contributors, data/metadata curators or data/metadata publishers. To avoid confusion (some of which has already materialized) between the individual software systems involved and the capabilities that LSE-490 refers to as “a system”, we will deviate from LSE-490’s current language to refer to the latter as the observatory logging ecosystem (OLE) (and propose that LSE-490’s language is amended to that effect).
Another point of confusion is the collision between LSE-490’s language and the fact that many people understand a “logging system” to be a system (such as Elasticsearch or Graylog) whose purpose is to allow the capture, storage and analysis access to software logs (including operating system logs). We will use “log management system” (LMS) to refer to such systems. In fact LSE-490 does not address a log management system, however we will argue that an LMS should be a participant of the Observatory Logging Ecosystem.
Finally, LSE-490 appears to describe a webapp for guided interactive access to data sources in the OLE. While we agree that such a webapp should exist as it would be evidently useful to observatory staff, we would like to stress that from a software engineering point of view, our focus is to ensure that APIs exist that can serve (in a distributed and also network-isolated way where necessary) the data from participating systems so that it can be accessed in a number of different ways, and that care should be taken for a clean separation between user interfaces and data access backends.
3 Observatory Logging Ecosystem (OLE) participants¶
Participants in the Observatory Logging Ecosystem are:
- Systems that provide data listed as “inputs” in LSE-490
- APIs that make that data available to UIs (using the word UI somewhat loosely to mean not just direct User Interfaces but services with their own user interfaces, eg. nbreport)
- Either dedicated (webapp) or generic (nublado) UIs for working with this data
- A&A service(s) for any UIs that require them
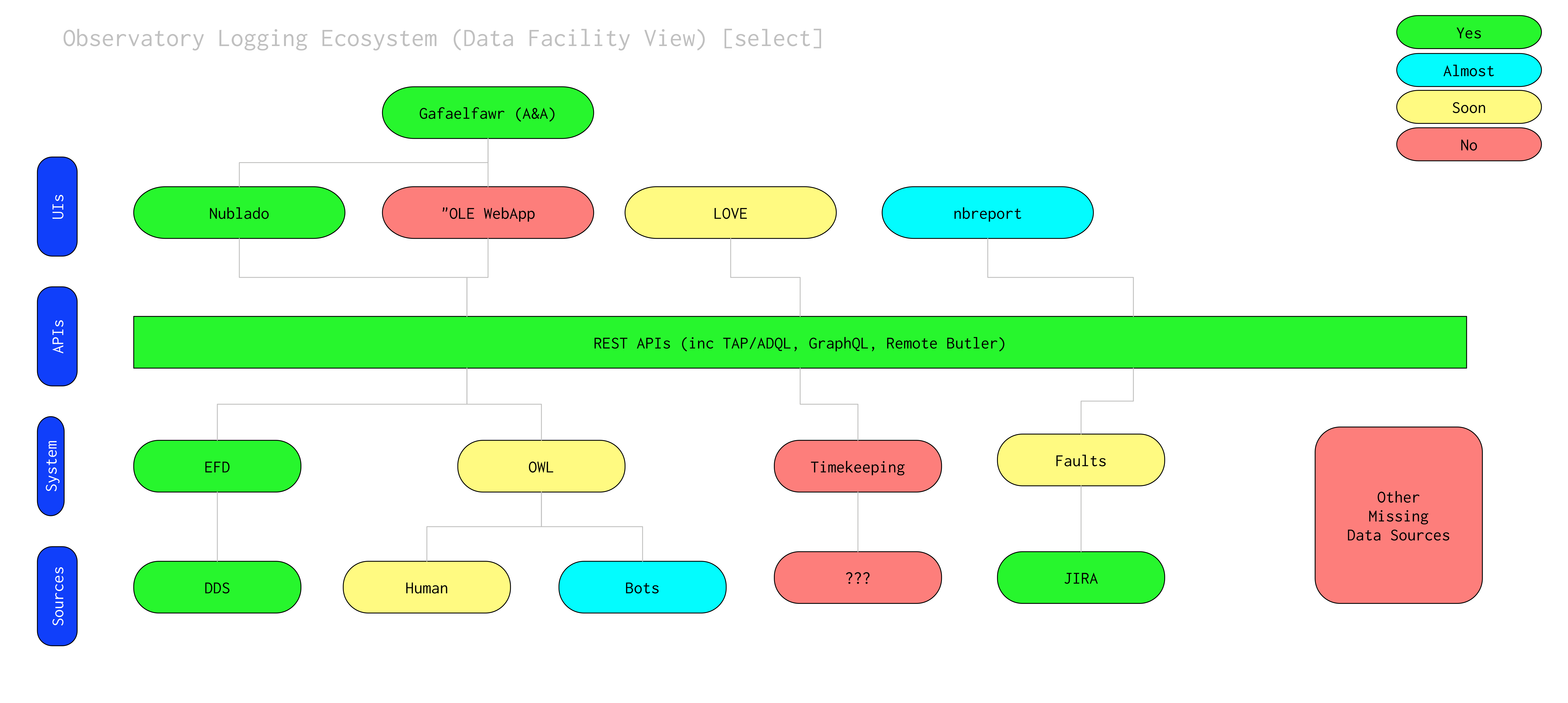
Figure 2 Overview of the proposed OLE architecture
Some of these participants are reasonably mature systems that already provide APIs to make their data available (eg EFD); others are not currently planned nor resourced to be delivered with the capabilities the Working Group required.
Missing Components
The missing components are:
- A system for exposure-level and narrative human input. This is nicknamed OWL (Observatory-Wide Logbook, in reference to the traditional paper logbooks of yore) and a prototype development is currently funded via LCR-1203
- Timekeeping (One can argue with LSE-490 as to the interface but the data needs to be captured)
- Observing script execution database to report on reasons why an observing script execution failed without burying the information in general log files??
- Machine readable duty roster (unsure whether planned, but simple)
- Maintenance activity API (unsure whether one exists or what it looks like) (CMMS?)
- A WebApp provided guided interactions with OLE data sources
- Templates for generated reports (relatively simple if all APIs are extant)
- LOVE interface (operator-friendly data entry to OLE systems and displays)
- JIRA Project Setup (metadata required by OLE needs to be API accessible)
- Survey Progress DB (is this part of the scheduler?)
There are also some cases where it is not entirely clear whether planned functionality would meet the aims that the Working Group had in mind, eg. whether “QA reports” are reports that can be generated from SQuaASH/faro data, for example.
A necessary step is for each of these components to be:
- Identify the T/CAM that could provide them
- Get an estimate of additional resources required (depends on technical stack and assigned developer) and whether it is likely for those resources to be available out of construction
- While an LCR to cover construction effort and plan ops effort for anything that cannot
It’s worth noting that in some “missing” cases it’s not obvious who the relevant T/CAM would be.
4 Observatory Wide Logbook¶
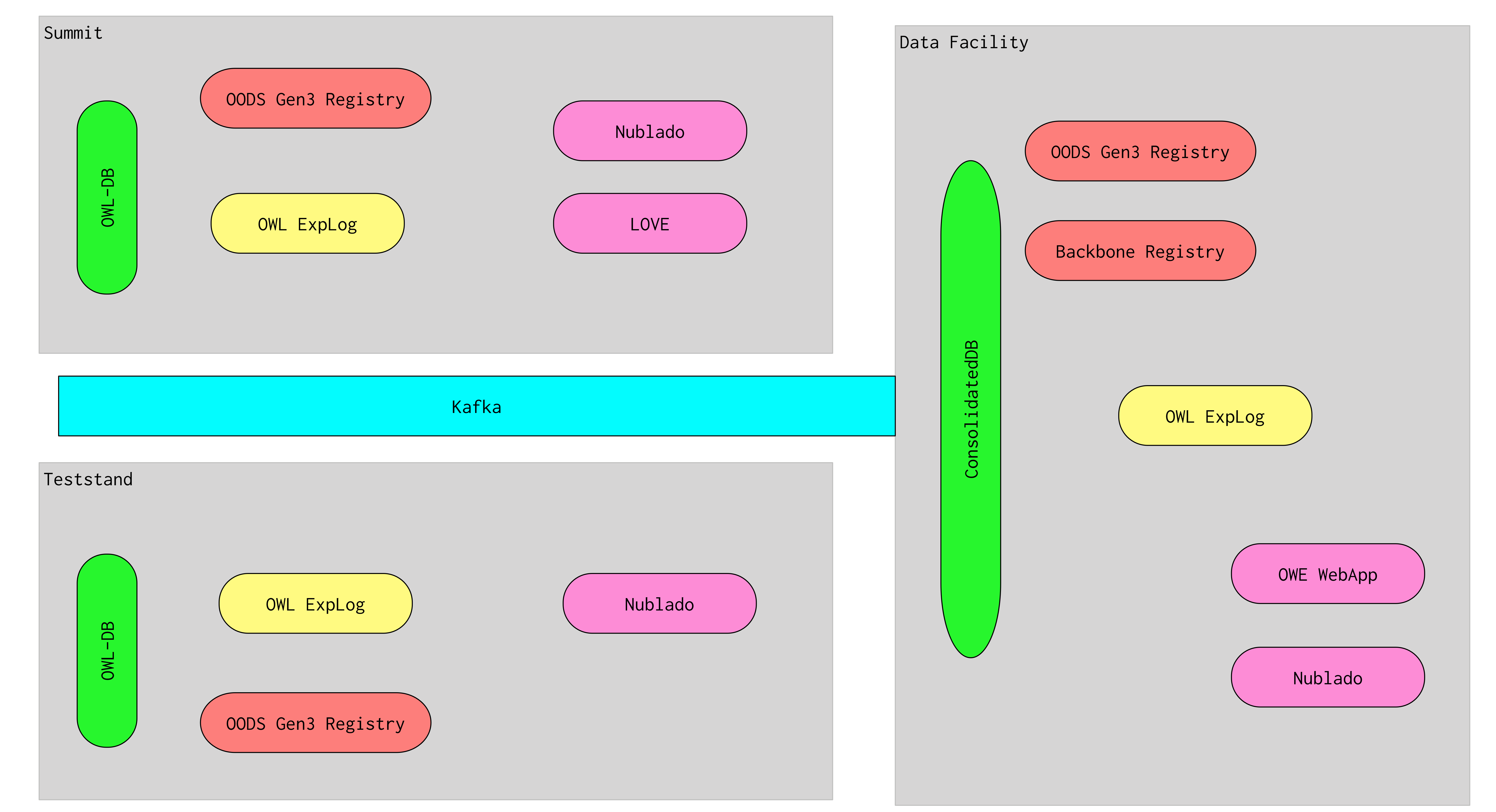
Figure 3 OWL provisional architecture
5 Networked Architecture¶
There is a requirement for summit access to data from OLE participants as well as for data to be synced to the Data Facility in order to be accessed by non-summit staff and more services. The details of how these requirements are services depend on the individual systems. For example for EFD data:
- access from the summit would be via Influx clients (such as Chronograph or our efd client python package);
- “syncing” to the Data Facility occurs via transmission of EFD data via Kafka;
- EFD data becomes accessible (at low latency) via a number of methods such as Chonograf (raw telemetry), TAP (consolidated telemetry) or parquet files (raw telemetry)
Each participating system must provide an equivalent data flow, or provide a workaround for summit network interruption. For example, if the fault system is hosted in JIRA Cloud, fault information can be recorded in a local file and faults could be filed after network connectivity resumes.
Summit users have certain high availability requirements but they also have a reduced need for certain UI capabilities such as (for example) accessing weekly reports. “Convenience” UIs such as the OLE WebApp should be hosted at the Data Facility to avoid unnecessary user access to summit systems; if some of the information exploration is critical to summit staff in the event of network failure, alternative methods (LOVE, nublado) should be provided to it.
6 Authentication & Authorization¶
SQuaRE services, including Science Platform and the EFD, are authenticated via the Science Platform A&A Service Gafaelfawr which currently can service authentication requests either from CIlogon or from Github and then issues tokens that can be consumed by various services and APIs. If the unnamed OLE WebAPP shares Science Platform deployment infrastructure (which would be wise), the A&A requirements in LSE-490 can easily be fulfilled.
LOVE authentication happens via (??)